← go back
ENTROPY EXPLAINS EVERYTHING?
April 27 2026
Entropy explains everything. I mean everything, including you. It explains how intelligence works. If you want a TLDR, I theorize that loss function for life is minimizing entropy over the time axis. Let me explain.
What is Entropy?
First, what is entropy? Well, entropy is a loaded term as it comes from two different fields: information theory and thermodynamics. The cool thing about entropy is that it is actually a law of the universe, being the Second Law of Thermodynamics. The law states that entropy always increases. This is readily apparent in our world. Have you ever seen a dystopian movie of a ghost city covered with leaves? That is the result of entropy. Ever noticed how things start to break down over time? That's the result of entropy. It is a powerful force, and it will never stop increasing. Remarkably, life is unique in that it actively pushes against this force. We are able to fight entropy, but it requires a lot of time and energy. It requires us to repaint our houses, repair our automobiles, and to sleep and eat.
So, while it sounds exotic, you have first hand experience with entropy. Everything you do and experience, in some way or another, is accompanied with it. Let's dive into some theory about it and derive it from first principles.
Concretely, entropy is a scalar variable that quantifies the amount of disorder a system has and is always greater than or equal to zero. There are actually a few different types of entropy. The entropy from physics can be written as Gibb's entropy,
where is the entropy, is Boltzmann's constant, is a microstate, and is the probability of the microstate occurring in a classical system of discrete energy microstates.
The cool thing about this is that this formula comes up in a seemingly totally unrelated field, information theory. Entropy in information theory can be written as,
where is the entropy, is any value of random variable, and being the probability of the random variable having that value. In information theory Claude Shannon proposed this as being the mathematical minimum number of bits needed to losslessly compress a source into a channel.
It may or may not be surprising to see that the Entropy from information theory has another interpretation. One can view it as the expected value of the self information of a variable's potential states. In order to understand this, suppose there is a probability of something happening. Since the logarithm is a monotonic function, it is valid to also define the log probability . For probabilities , the logarithm is negative. However, negative probabilities don't make sense, so we multiply them by so the probabilities become positive. With this negative, we end up with the definition for the self-information, or surprisal, of an outcome of a random variable, . We can also view this as the amount of information we are given if this one event occurs. Low value is low surprise, so we had low uncertainty that it would happen. High value is high surprise, which meant that we are now in a situation that we didn't predict.
In order to gain intuition for why defines the uncertainty, suppose that we always know what the value of will be, so . Plugging this into the logarithm, . This means that the uncertainty is zero, which makes sense since we always knew what the value of would be. Now suppose that we know of the time the value of . The uncertainty would be , just a bit higher than when we always know what it is. We can see that as the probability of goes lower and lower, nearing a zero percent probability, that the uncertainty formula will be higher and higher. We can see this by graphing the uncertainty formula:
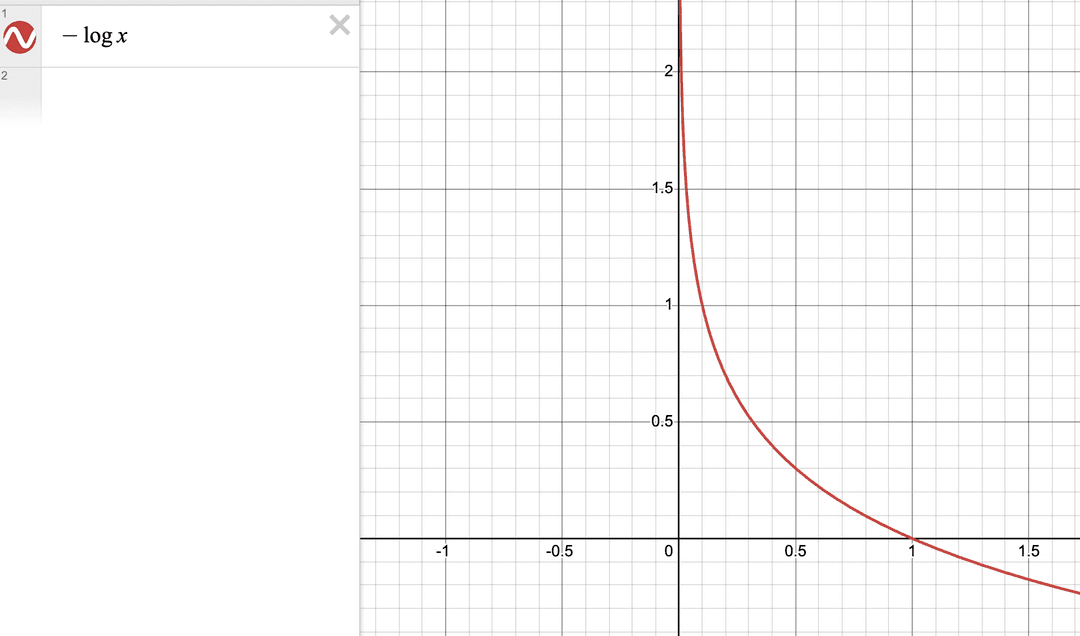
We can see that at , the uncertainty is zero. As we approach lower probabilities of then the uncertainty exponentially increases. If it is near , then the uncertainty goes to infinity. This makes sense because the probability of something is never zero, even if its a trillionth of a percent, there is a chance that something it could happen, however we would be very surprised if it were to occur. For example, pancakes could start falling out of the sky because the pancake alien invasion started happening. Extremely unlikely, but could happen.
Okay, hopefully now we have an intuition for the uncertainty formula . Wasn't this post about entropy? Well, entropy is the average value of the uncertainty, . This means that entropy is the average value of all the uncertainties in our system. Add all of the uncertainties for each value of x, and weight each term by the probability.
Notice that this is the definition of Shannon entropy.
Minimizing Uncertainty
Okay, we understand what entropy is. It is a number that quantifies the average uncertainty of a variable. How does this explain "everything"? Well, I have a theory that entropy is formula for which life and intelligent behavior arises from.
That's right. You. Me. Your mom. Your dog. Your fish. Even the micro-organisms. Everyone.
Why would I think such a thing? Aren't humans vastly more complex and smart than other animals, let alone micro-organisms? How could we all come from the same formula? Well, we have a couple of clues leading us to this conclusion. The first clue came to me in March when I saw this video. Watch it, it is pretty cool and has Pink Floyd playing in background.
Okay that was kinda crazy, the organism just split in half and then somehow came back together. That was my first reaction and so I liked the video, and continued scrolling. However, a week later, I stumbled upon this video again while searching through my likes and noticed something very interesting. You can see in the bottom right a fish-like looking organism. It goes into the tunnel, stops, tries to squeeze through, realizes it can't, and then backtracks and starts exploring elsewhere. Woah! I didn't expect this type of behavior, it almost reminds me of a cat exploring its environment. It turns out that this is called a Paracelium. The big yellow ones are called Stentor. Remarkably, none of these animals have brains, let alone even a single neuron. How can they move around? It turns out that they have these things called cerebral ganglia which acts as a sort of brain, but isn't anything like our brain. This is interesting. Something that doesn't have a brain and doesn't have neurons seems to explore its environment in a relatively smart way. This isn't just random, at least I don't think it is. So this was the first time that I realized that complex behavior doesn't require a brain. I looked into it, and a couple weeks prior a lab from Harvard just so happened to publish a paper on the Stentor, finding that it displays Pavlovian learning and doesn't have a brain. I found this cool but didn't know how to act upon this information.
So we learned two facts: you can learn without a brain and micro-organisms explore their environment. Interestingly enough, I am currently doing my thesis on exploration for AI algorithms. To date, I haven't seen any AI agent replicate this type of behavior. AI has learned how to do amazing things, but nothing that moved around and reminded me of a living being like some type of bug or cat.
A lot of people think that this could be explained by instinct or some type of intuition. This could very well be correct, but the problem with this explanation is that its very unsatisfying. HOW is it instinct. HOW did it learn to do that? Evolution? Sure, that's correct, but then you remember that you're not better than Mother Nature and then take it for granted.
So, even though it might be correct, I want to refrain from explaining this behavior being intuition/instinct and being developed by evolution. Instead, I want to ask HOW can we build a similar system? HOW can we create digital life?
Let's start thinking from first principles. Clearly, all animals want to survive. In mathematical terms, we can write this down as , the probability that you survive. Ideally, we would like to maximize the value of survival, that is, we want to maximize . Great. Is it even possible to compute this? In some magic way, animals somehow know to take actions that maximize their probablity of survival. The reason why you eat is to maximize survival. The reason why you sleep is too. However, how do we exactly determine the probability of survival? Is there a formula for that we can just plug numbers into and get the survival probability?
Well, lets massage this formula. Let's take the logarithm, . Then, let's make it negative so that the probabilities are positive. Wait a second! We now have the formula of uncertainty! This is magical as we have just shown that uncertainty is mathematically equivalent to survival. Since we took the negative, maximizing the chances of survival means minimizing uncertainty.
The great thing about this is that minimizing uncertainty is computable, and interestingly, requires minimizing uncertainty with respect to something, ideally minimizing uncertainty for one's self. This gives us a self-centered, intrinsically motivated agent. Everything this agent does is in order to minimize uncertainty about its current situation. This agent is you. Its me.
The idea that all we are doing is minimizing uncertainty might seem a little weird at first, but once you think about it, you realize that it offers an explanation for nearly everything.
For example, suppose you are walking outside in the park. You see a bird fly by. Perhaps something like this:
Throughout the video, you automatically focused on the bird because it was the greatest source of uncertainty in your environment, and you wanted to minimize that uncertainty. Perhaps you looked at the black part of the screen a couple times, in order to make sure you weren't missing something. "Automatically" looking at the bird feels like an instinct, but that isn't a useful explanation. However this can be explained via a framing of minimizing uncertainty, and I'm starting to think that Attention and minimizing uncertainty are closely linked.
Suppose you are walking in a park and you pass a group of people walking by. Why did you notice that? You noticed that because it was the greatest sense of uncertainty in your environment, and you wanted to minimize it. You hear a twig snap behind you, and you look behind and notice a squirrel looking at you. Why did you look behind? You looked behind because you wanted to make sure there wasn't a tiger ready to pounce on you and needed to make sure you didn't need to start running away. Silly example, but minimizing is starting to seem like it can explain all our behaviors.
Another example: You are looking at these words right now. Why are you looking at these words right now? You are looking at these words right now because you want to reduce the uncertainty of what I am talking about.
Another another example: It is known that babies look at more attractive people for longer? Why is this? How do they know that someone is attractive? Well, if you look at the models posing for your favorite clothing company, you'll notice that they have very predictable features. They have a symmetrical face, and clear skin. There is little uncertainty here. Take a stereotypical ugly person. Teeth going in all directions, unkempt hair, holes in their shirt, and oddly colored blemishes on their face. This is all highly uncertain and is displeasing to look at. Thus, we can explain the reason that babies prefer looking at attractive people is because they have a sort of pleasing predictability that calms them down as they are viewing something that is at a low uncertainty level.
Another another another example. Ever got a song stuck in your head? It just seems to repeat over and over again. What is happening here? Well, somehow your brain can't quite predict what is happening in the song. Perhaps there is a certain word missing or a note that you can remember. Usually it keeps being stuck in your head, but once you hear it again, it magically it goes away. Again, we see a seemingly complex behavior come from minimizing uncertainty.
Hopefully you get the point by now. In fact, I encourage you to think for a moment if this is what you are doing. Perhaps you just thought about something, or planned something in your head. Did you just scratch your ear because of wanting to minimizing uncertainty? Whatever it is, are you minimizing uncertainty?
Minimizing Entropy
Okay great. Minimizing uncertainty explains a lot of behaviors. However, it doesn't explain everything. It is close, but incomplete. What makes it complete is minimizing not just your current uncertainty, but your uncertainty over time. What is uncertainty over time? Entropy. It is the average of uncertainty, which can offer an explanation for why we don't just lock ourselves into a dark box. Clearly, a dark box is very low uncertainty. There is nothing to see, nothing that can cause uncertainty. Why aren't we confining ourselves into a dark box? It is well known that when we put people into the padded rooms, insanity occurs. Therefore, we are not minimizing uncertainty. Theory busted.
The explanation to the dark box is that we DON'T average uncertainty. We have defined it to be the immediate uncertainty, just being the uncertainty at this current time. Instead, we actually aim to minimize uncertainty over time. That is, we now take the long-run average of uncertainty along the time axis. How can we write the average uncertainty over time? ENTROPY!
We minimize entropy over time and our state at the current . This can explain everything we do. Entropy explains everything.
The reason why this works is because, if we aim to minimize entropy, we are allowed to have temporary increases in uncertainty, but only as long as this leads to lower average uncertainty over time. That is, as long as the average uncertainty over time is lower, we can afford high uncertainty states. In order to do this effectively, we need a sort of "world model". We need a way to plan out different actions in our head and see how they will affect the world around us, and determine the best course of actions to take that will lead us to lower entropy. This minimizes uncertainty, which is equivalent to maximizing survival.
The dark box was an example that simply minimizing uncertainty failed to explain. However, minimizing entropy resolves the situation. If we minimize entropy, then being in a dark box is TERRIBLE. Over a few minutes, we will start to worry about what is happening outside the box. Our mind will start racing. Did WW3 start? Are the aliens invading? Who won the sports game? What am I going to eat? With our world model, we would be able to predict that putting ourselves inside of a dark box actually leads to very high uncertainty over time. Instead, we would laugh at that idea and go about our day, hopefully one with low entropy.
If we all we are doing is just minimizing entropy over time, then wouldn't entropy be most minimized if an agent ends itself instantly? This might seem like a valid counterexample, entropy is zero if you aren't alive. However, if you consider the entropy over time, this is a very high uncertainty action because as time goes along (by The Second Law of Thermodynamics), entropy will increase unboundedly and you will have no way to prevent it. You would be stuck in a state in which you cannot further minimize entropy over time. The key distinction is over time. If you were only acting greedily to minimize entropy at your current step, then you would be shortsited to go into the terminal state. This is the exact same as locking yourself into a dark box. Minimizing entropy over time offers an explanation for why entering terminal states wouldn't be the default action.
Relation to Max Entropy
Maximizing entropy is a common technique in reinforcement learning. The reasoning behind it makes sense. Suppose you can go left or right. Both lead to the same outcome. Instead of committing to one direction, we would like to place equal probabilities to both left and right. This maximizes the entropy of your actions. Suppose the left side had a bride that fell down, a deterministic policy that always chooses left would fail. Instead, the high entropy policy correctly picks right. This offers an explanation for why max entropy policies are robust. They also lead to a form of exploration, as spreading out actions over time means you take unlikely actions more often which could potentially lead to new states.
We also see methods that maximize other types of entropy, like state-space entropy or some measures of maximizing mutual information or minimizing prediction error.
We differ in an important way. Instead of maximizing, we minimize entropy. We aim to minimize the entropy of high dimensional observations of states along the time axis . I call it long-run entropy. While this might seem like a contradiction, taking the action that leads to the minimum long-run entropy over time means you might need to take high-entropy temporarily, as long as it eventually leads to the miniumum entropy. The expected value allows you to have transient max entropy, which is necessary in certain cases, as we saw in the above examples.
Relation to Karl Friston
Minimizing entropy is very similar to work done by Karl Friston with Active Inference and the Free Energy Principle, who actually got me to start thinking about this stuff. Importantly, we improve on his work in three major ways:
-
We don't define a variational bound for surprisal. Instead we allow for the use of any mathematical modeling techniques (score matching, flow matching, diffusion, you name it).
-
We don't define any priors. This is a crucial fix as it allows us to learn on the go with no prior information from "evolution" or require defining "instincts". In theory, our method would be bootstrap itself from nothing.
-
We strip everything down to bare essentials, only requiring a singular function to learn. It is the world model, , and is the only component necessary to accurately allow us to determine long run entropy of a state given action . It is clear to see that this is a useful component because your brain has a world model and is what allows you to imagine things in your head. For example, imagine a red apple spinning around. Then imagine it dropping down and you catching it before it hits the ground. That's your world model, which works entirely in latent space.
As minimizing entropy is a loss function, I will denote it with the notation commonly used for loss functions: fancy L, with entropy of observations
Relation to Reinforcement Learning
It may seem that this is some type of reinforcement learning problem because we are actively taking actions in an unknown environment. Indeed, there are some similarities in setup. We see similar notions such as states, actions, and intrinsic curiosity. One could define a policy can be constructed from the world model, e.g. agents greedily taking the action which most minimizes long-run entropy. Finally, one might be able to take the entropy at each step as a reward.
However, in order to satisfy stationarity, reinforcement learning requires the reward function to be a fixed over time. This does not hold for our method, as the policy comes from the world model, which is dynamic and changes over time. Thus, minimizing long-run entropy is not an RL problem.
Exploitation vs Exploration
Interestingly, I believe that minimizing long run entropy implicitly gives a solution to the exploration vs exploitation problem. The formula allows the agent to determine at each time step whether exploiting or exploring best minimizes entropy. Amazingly, it arises from a single loss function that can be derived from first principles, is equivalent to maximizing survival, and exploring or exploiting would be a completely emergent property. With this, I theorize that this is the loss function that all life abides by.
Next steps and limitations
So, we have a hypothesis that minimizing long-run entropy is the objective that all living beings optimize. In order to test this hypothesis, we need get experimental evidence. Experimental confirmation would be detection of emergent behaviors arising from it, displaying similar behaviors to animals. This would be an ongoing process, needing to show the most basic to the most complex behaviors. I think that the examples we went over would be a good place to see if our agents can also exhibit similar behavior. For example, does it learn to focus on a flying bird? Does it learn to avoid terminal states? It would be interesting to see if it learns get avoid the "noisy tv" problem.
If this loss function is correct, then minimizing it gives us only half of the answer to creating digital intelligence. The other half of the answer involves creating a powerful world model that allows a digital being to predict the effects of its actions on the world and be able to plan out action sequences that best minimize entropy.
To date, no one has made a world that is as capable and as power efficient as a human world model that can exhibit remarkable complexity in its actions. Determining if we have a powerful enough world model is also a chicken and the egg problem. In order to get emergent behavior, we need a powerful world model, but in order to know if we have a powerful enough world model for emergent behavior, we would need to see emergent behavior. Additionally, with current modelling techniques, one would likely need access to a very large amount of data and compute in order to reach the capabaility of human-level world models.
Conclusion
Minimizing long-run entropy is a beautifully simple theory. We have a simple loss function and require only a singular function. This is bodes well on our side, as the most fundamental truths in our world are beautifully elegant.
Can digital intelligence arise from reducing long-run entropy? Time will tell. Until then, keep fighting your eternal battle of minimizing uncertainty against The Second Law of Thermodynamic's ferocious wave of ever-increasing entropy.
Citation
Please cite this work as:
Buhler, Kevin. "Entropy Explains Everything". kevinbuhler.com (April 2026). https://kevinbuhler.com/blog/entropy
Or use the BibTex citation:
@article{buhler2026entropy,
title = {Entropy Explains Everything},
author = {Buhler, Kevin},
journal = {kevinbuhler.com},
year = {2026},
month = {April},
url = "https://kevinbuhler.com/blog/entropy"
}
Appendix
Active inference is equal to learning a world model
One can feel free to skip this part, where we derive some forms of variational lower bounds and show that it is a special case of learning a world model. That is, learning a world model can be derived from the variational free energy lower bound.
FORMULA #3: VAE FORM (Complexity - Accuracy)
We assume random variables = input = latent.
We want to learn a world model that closely matches (means it is a good predictor). However this is intractable unless you are god and have direct access to the simulation. So we introduce an approximate (variational) distribution which approximates the true posterior .
Apply Jensen's inequality
Derive to ELBO
KL form:
Maximizing this is equivalent to minimizing the negative ELBO
We can see the second term as an encoder-decoder. gives a latent vector given input. Then takes that latent vector and tries to reconstruct the original image. The first KL term is a regularizer towards a prior that is usually guassian .
But why is this useful? We can gain intuiition from another perspective.
FORMULA #1: KL FORM
We know that from Bayes rule that
If we assume that is a constant, we can take an expectation and it won't change anything since an expectation of a constant is a constant. So lets take with expectation to q(z|x)
Since is a constant the log gets pushed in
First term is the ELBO and the second is KL divergence
Equivalently
The KL divergence is always non-negative and is constant. Beautifully, this means that maximizing means is minimized and pushed closer to the true posterior.
FORMULA #4: ACTION CONDITIONED WORLD MODEL
We made a pretty big assumption: is a constant. Imagine you are strapped to a rock and can't move. If this is true, then yeah is conditionally independent from any action . The only way to learn the true posterior (maximizing elbo) is to update your brain that whatever you're seeing is more likely (this is perception and what we see in the previous formulas). However, there's actually a hidden here , which works because previously was a uniform distribution independent of the world model which never changes any observations, so it was able to be taken out of the equation. So in this model, . As we've said, this is only a correct assumption for when you're strapped to a rock unable to move around and only able to learning with your eyes.
If you aren't strapped to a rock and can move around, then you actually can effect the depending on what actions you take in your environment. In this setup we need to introduce the notion of taking an action , and need a function that models how this effect changes the world. Mathematically we can see this as . Note that the previous assumption doesn't hold anymore, $p(x|a) \neq p(x)$$ (action does change probability of future observations). This is known as an action-conditioned world model.
In order to e.g. minimize uncertainty in the future, we must be able to model the affect of our actions. This generates a trajectory of actions to take and states we end up in. Then we choose the one that satisfies our objective the most (like minimizing uncertainty). This could make it so that we actually temporarily increase uncertainty, because long term the expected value is actually lower uncertainty.